AI Safety Fundamental Final Project
Investigating Local circuit in the feature basis
For a complete technical explanation of the methods, visit the following Streamlit App
This post is part of the Final Project for the AI Safety Fundamentals Course it complements the Streamlit app, which I recommend to anyone who’s interested in AI Safety.
This project has spanned 1 month and the final product is an implmementation of various techniques used in Mechanistic Interprtability for finding local circuits in Language Models.
This project started with a grandiose objective; Investigate multi-token circuits in the wild
In this context Multi-Token refers to, circuits that explain a behavior over multiple tokens, (eg. A neuron fires in 3 consecutive tokens, for US States., not just to circuits that span multiple token positions)
This initial efforts to accomplish such ambitious research were frustrated by the technical difficulties with the required tooling.
Despite the hardships, I’ve carried trough with the project to the best of my abilities and I’ve accomplished ~60% of the initial goals.
At the end the project, was mostly unchanged with slight modifications make it feasible with the available time.
What sections should you read
| ¿Doe the title sound interesting to you? | ¿Are you familiar with MI? | Sections to Focus On |
|---|---|---|
| No | No | Motivation, Objective, Results |
| Yes | No | Motivation, Introduction, Relevant Definitions, Objective, Results |
| No | Yes | Motivations, Results , Frustration Dump |
| Yes | Yes | Motivation, Introduction, Relevant Definitions, Objective, Methods, Results, Frustration Dump |
Table of Contents
Motivation
It’s difficult to provide a reason that led me to choose this project as the public shareable result for the AI Safety Fundamentals Course.
From the beginning of the project, I was aware of the difficulty of the endeavor I was undertaking.
Whether I was being naive or courageous, I had the profound conviction that I needed to go hard, whether or not my taste for choosing was proper is up to the reader.
To be brief and stop yapping, the reason that I chose this project was because I think Interpretability is important.
¡¡¡I think that interpretability is important!!! And the state of the world is that we’ve gone from a barely useful GPT-3 to O1 in less than 3 years.
¡¡¡I think Interpretability is important!!! And Interpretability is uniquely well suited to leverage, the same driving factors that have propelled the growth in AI capabilities Scale, Search and Synthetic Data
¡¡¡I think Interpretability is important!!! And the flywheel just need to be kickstarted.
Introduction
Mechanistic Interpretability is a field of Machine Learning that is concerned with understanding, what internals of Neural Networks.
Most of the MI literature is focused in a certain kind of Neural Network, the Langugage Model, which is behind popular products like chat-GPT.
Most of the Language Models in the present are based on the Transformer which is a NN architecture introduces in 2017.
In the simplest terms Transformers are composed of stacked Transformer Layers, which in turn are composed of Attention Layers and MLPs.
All the layers are connected by a Residual Stream which can be thought of a large shared communication line, which enables trans-layer communication.
-
Attention Layers are composed of Attention heads, and can be thought of as components that: 1) Select the information to attend to. 2) Extract information from the context.
-
The MLP layers are composed of neurons, that further process information present in the residual stream (including the information from the Attention Layer)
Despite the simple nature of the elements that compose the transformer, understanding even the most simple model behavior proves to be extremely challenging.
Many reasons are behind the difficulty of understanding a model behavior from it’s internals, but at high level I can name a few reasons.
- The sheer number of components,a amounting to millions of individual neurons.
- Neuron superposition and polysemanticity.
- Tradeoff between explanation length and accuracy.
- Model’s sensibility to changes in the input.
- Lack of good metrics, to measure a behavior.
Neuron polysemanticity and superposition are, two different but strongly related hypothetical properties of Neural Networks, feature superposition is a claim grounded in theory (aka Johnson-Lindenstrauss Lemma) which states that a model can represent more features than neurons have.
The definition of a feature is somewhat contested but I will role with "A feature is a property of the input"
Neuron polysemanticity is an observed phenomena in which a neuron fires in seemingly unrelated context.
Neuron polysemanticity was a major problem in mechanistic interpretability, holding back the field.
Hopefully neuron superposition has been partly adressed in the last year with the introduction of dicitonary learning techniques, mainly Sparse Autoencoders.
The basic principle of sparse autoencoders is that, we can train a model with a simple objective like reconstructing the model activations, and by applying simple constrains like sparsity and an basis overcompletness we end up with a model that can reconstruct activations into sparse and Monosemantic features, that are also human interpretable.
For this investigation I leverage Sparse Autoencoders and Transcoders to investigate local circuits in GPT small.
Relevant Definitions
Mechanistic Interpretability has plenty of jargon and concepts that are difficult to grasp without context, unfortunately I don’t think it’s possible to introduce the concepts with enough depth to go from 0 to fully understanding the techniques used, which some of the are fairly new.
Hence I will ask the unfamiliar reader to trust their intuition for what things mean and to check some of the references and codebase for extrainformation.
For the reader who’s familiar with prior literature I ask you to apriori trust my understanding of the concepts, and regard things that doesn’t make sense to you to artifacts to the comunication.
I don’t really know who (if any) will be the public of this read, so it’s diffiult to gauge the degree of prior knowledge that I should assume.
Neural Network Activations
Activations are the intermediate computations of the model components.
We can access the activations of a transformers with multiple levels of granularity, the important takeaway is that for each token position and each layer we have:
- A resiual stream (d= 768)
- An attention layer input and output (d = 768)
- The MLP layer with input and output (d = 768)
At each layer the outputs of the MLP and Attn Layers are added to the residual stream, they share dimensionality.
Sparse Autoencoders
Sparse Autoencoders (from now on SAEs) are a dictionary learning technique, that consists on training a model to reconstruct model actiavations (the location can be the residual stream, the Attn Output or the MLP output). By imposing a constraint on sparsity and using an overcomplete basis we obtain a set of sparse, monosemantic and human understandable features.
Transcoders
Transoders (from now on TCs) are a variation of the SAE, with the difference that instead of reconstructing the activations from some location, TCs approximate the computation of an entire component (mostly the MLP layer).
The main difference between the MLP and a TC trained to behave like an MLP is that the TC is trained with and overcomplete basis wrt the original MLP and sparsity is enfored in the same way as in SAEs.
The sparsity enable us to treat the TC as linear, since the sparsity enforeces a kind of input independence.
Very important!! Trough out the remaining of the post whenever I say SAE in general I’m refering to both Attn Output SAEs and MLP Transcoders
Features
Features are properties of the input, like the language of a prompt, the tone, or whether or not a US State has been mentioned.
Features are mostly believed to be linear (what does linear mean in this context is a rabbit hole by itself), in the sense that a feature is represented by a direction in activation space (high dot product in presence of the feature) In the context of Mechanistic Interpretability work that uses SAEs or it’s variations, the features are given by the SAEs.
If we reconstruct an activation with a SAE and the n-th SAE-neuron fires, we say that the activation contains the n-th feature from that SAE
In this project we use SAEs for the attention output and TCs for the MLP output, this defines a set of possible features that could be active for a given input.
Circuits
The term circuit has been used since the start of the field, and could mean to different things, that are very closely related. In the frist era of MI, a circuit is mostly a subgraph of the model’s computational subgraph (used in paper like IOI or ACDC), but also the term circuit has alsobeen used to refer to featuer composition (used in papers like Chris Olag Inception v)
This 2 definitions are really 2 sides of the same coin, and the possible gap between them is further narrowed by the introduction of SAEs.
One thing to keep in mind is that circuits are defined with respect to a task or model behavior that we want to understand.
Local Circuits
Local circuits are a kind of Circuit in the model behavior that we want to understand is not reflected in the output. For example the activation of a given neuron.
Circuits in the Feature Basis
Circuits in the Feature Basis are subgraphs of the model’s computational graph, when we include SAEs (and/or TCs) in the model’s forward pass.
Hence the node of a circuit in the Feature Basis are Features, rather thatn model components.
Objective
The main objective of this project is to understand which features in prior layers are relevant for the presence of a feature.
Note that, in this context the presence of a feature is the same as the fireing of a SAE-neuron activation
We call target node the feature who’s fireing behavior we want to understand.
We want to understand which features in lower layers are present when the target fires. To do so we gather a dataset of examples in which the target feature is present, this dataset is obtained trough the nueronpedia API.
Concretly our target nodes are some MLP fetures in the layer 5 taken at random.
Methods
In this project we investigated local circuit in GPT2 small, mainly:
We investigate in which conditions certain features fire, concretly we investigate why MLP features in the 5-th layer fire.
To do so we use an attribution techniques to discover which upstream features are more influential for the fireing of a given target feature.
We use Hierarchical Attribution, a technique introduced in "Automatically Identifying Local and Global Circuits with Linear Computation Graphs".
Hierarchical Attribution differs from direct attribution in that it detaches unimportant nodes in the backward pass, instead of after the backward pass.
The use of Attn Output and MLP Transcoders allow us to treat the computational graph as a linear graph (if we freeze the Attention Pattern).
Once hierarchical attribution has been performed we can use the OV and QK circuits to obtain relevant edges between the feature nodes resulting from the hierarchical attribution.
Results
At the time of writing there are no gold standard ways of evaluating circuits. The main 2 metrics that we are concerned for circuits are Completness and Faithfulness.
To measure this metrics we require node-wise ablation, which is costly.
One proposed metric to measure the faithfulness of a Linear circuit in “Automatically Identifying Local and Global Circuits with Linear Computation Graphs” is to take the fraction between the target activation and the sum of the leaf node’s attribution.
This is useful since works out of the box, and there’s no need to worry about taking the model OOD, which sometimes happens when performing ablations.
This only works because we’ve made the circuit full linear with the introduction of Attnetion Output SAEs, MLP Transcoders and freezing attention patterns.
Attribution proportion vs Threshold
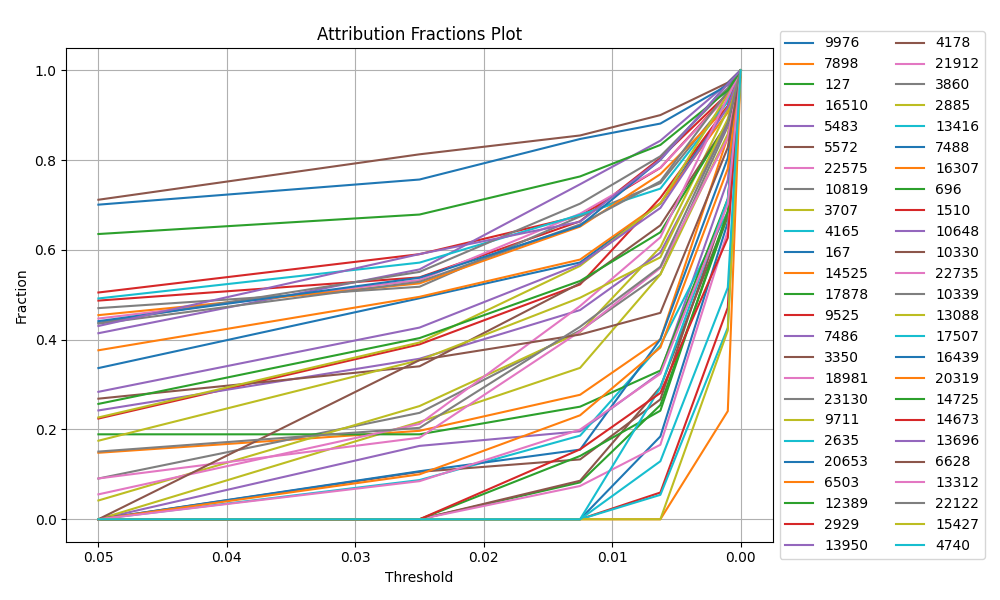
Due to the difficulty of evaluating the circuits, and the lack of gold standards we focus more in measuring key metrics between circuits.
After performing Hierarchical attribution, we can concatenate the attribution scores between components, this results in a extremly high dimensional tensor that represents the most important faeture to explain the fireing of a target node.
This tensor can be further reduced by aggregating across token positions, this results in a tensor with shape (1 x all_feats) that we call computational trace.
We can compare the computational traces across different target features, or across different prompts that make a target feature fire.
Some interesting facts about the computational traces are:
Disclaimer This plots are somewhat cherry picked, the plots for all the features can be seen in the Streamlit App
There’s an apparent linear relation between the average pairwise trace similarity and the activation of the target node.
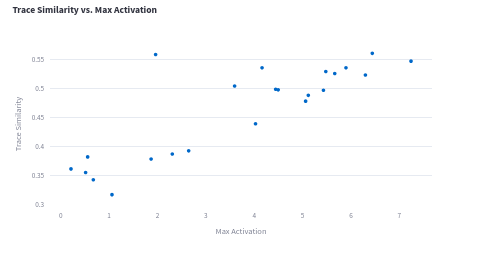
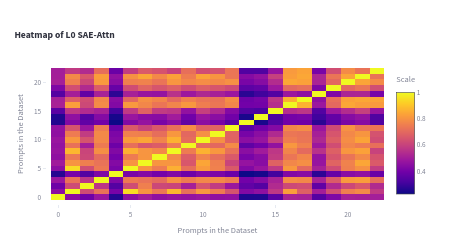
We can see what are the most important components by analyzing what components are more similar for the dataset traces.
For a given target feature, some of the examples are moere similar between them at various component locations<p align="center">
This heatmap is for the attention features in Layer 1.
 </p>
</p>
We can see how all the examples for a given target feature converge trough the many components.
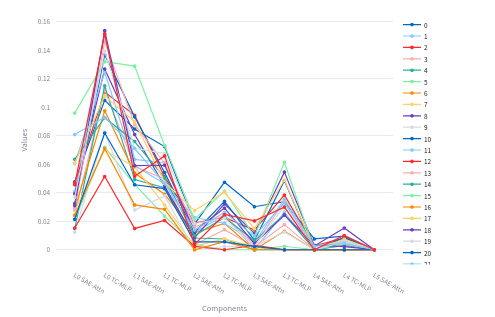
Frustration Dump
I’ve rushed to write this section,for the reader take into account that most of my complains are probably just skill-issues, and that is not a critique to other peoples work, just my POV.
During the project duration I’ve stumbled with countless problems, ranging from software bugs to lack of implementation details usually I wouldn’t spend time in enumerating the problems that I’ve run into, because negativity is viral but some of the difficulties I think are paradigmatic of MI research and it’s good to keep them in mind.
1) Problems with general tooling, Mechanistic Interpretability as a field is in the expansion phase, this results in high Opportunity costs for researcher that want to refine tooling.
2) Problem with the SAE framework, I’ve spent more time that I would like to admit browsing trough neuronpedia, and it’s apparent that neither the explanations nor the feature’s itself are the most informative (specially for the smaller SAEs), being that most of the feature’s behavior is dominated by the token position.
It’s important to separate what you expect to find and the evaluation of the actual findings, but the quality gap between 32k and 1M SAEs is apparent in hindsight.
3) Memory constraints, with just some back of the envelope calculations it’s soon apparent that the naive “use SAEs” in all layers is not feasible, for >2B models.
4) The preponderance of the preprint, this is the case for the general field of ML, but this results in a situation in which the reader must “guess” what are the authors meant. I understand that the incentives right now are to not produce easily replicable research because the upfront cost for the researcher.
Thanks for reading.